Using simple language to ask questions is the most intuitive, efficient, and mentally effortless way to communicate. Wouldn't it be convenient if we could apply this approach to working with data?
However, the journey from thoughts to analysis to actions requires the extraction, modeling, and analysis of massive amounts of data, which demands multiple specialized skill sets.
As a starting point, we need to extract data from databases using SQL. Although SQL is powerful, it’s not user-friendly. Learning, comprehending, and effectively using SQL is time-consuming. Even after mastering it, repeatedly writing similar queries is not an enjoyable task.
This is where NLQ (Natural Language Query) systems come into play as a ray of hope to end this monotonous exercise. NLQ-to-SQL systems enable users to access and interact with data in an intuitive, conversational manner, similar to asking questions in simple language. This transformation empowers business users to make data-backed decisions without needing to learn SQL or relying on analysts. It also liberates analysts from repetitive reporting tasks, allowing them to focus on more strategic pursuits.
In a world where LLMs are revolutionizing creative fields and tools like Github Copilot are reshaping how engineers write code, NLQ-to-SQL is also seeing a renewed interest from several players. In this blog, we would share our experiences and learnings as we explored this possibility.
We would also discuss how we are utilizing the Jobs to be Done framework alongside LLMs to generate business value while addressing the common challenges associated with LLMs, such as hallucinations.
Breaking down the NLQ-to-SQL process
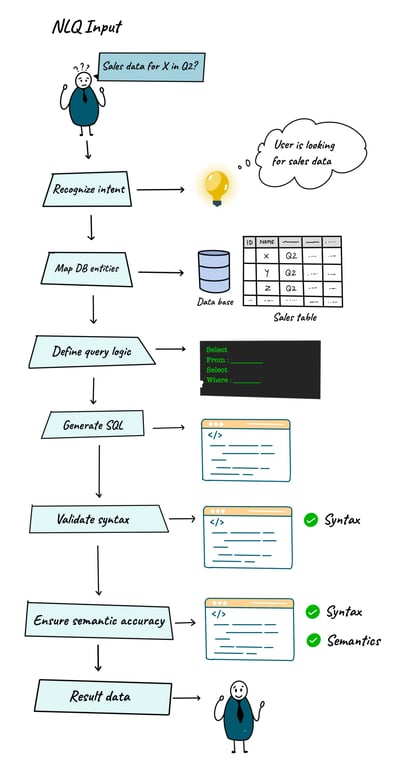
NLQ-to-SQL translation is a challenging task. Consider the question, “Can you provide me with sales data for Product X in Q2?” This seemingly straightforward query sets in motion a complex sequence of steps:
Intent recognition: First you need to decipher the intent behind the NLQ in the context of the business. Like, in the given example, the NLQ-to-SQL system must understand that the user is looking for sales figures.
Entity recognition: Once the intent is clear, the system must determine which tables, columns, and data sources are relevant to answer the query. This involves mapping the user’s request to the appropriate database entities.
Query logic comprehension: Subsequently, the system must comprehend the logic embedded in the NLQ and accurately translate it into SQL format.
SQL query generation: The system then needs to generate SQL commands that adhere to the syntax rules of the specific database being queried.
Syntax and semantic validation: Finally, beyond syntax, the system must ensure that the generated SQL is semantically accurate. The SQL should capture the precise meaning of the NLQ to provide relevant and accurate data.
Whether it’s a human expert or an AI/LLM system writing SQL, achieving 100% accuracy in NLQ-to-SQL conversion demands precise execution of each of these steps.
Journey so far and benchmarks
Pre-LLM
NLQ to SQL systems were explored as a use case long before LLMs became widely recognized. An important development during this period was the creation of benchmark datasets, with the Spider dataset being one of the most notable examples.
Imagine these datasets as repositories of past exam papers, but instead of traditional questions, they contain natural language queries and their corresponding ideal SQL answers. The Spider dataset encompassed 200 databases spanning 138 unique domains. Each entry paired a real-world NLQ with a gold standard SQL query, essentially serving as a perfect answer key.
This benchmark dataset set the standard for evaluating the accuracy of NLQ-to-SQL solutions. However, prior to the advent of LLMs, existing solutions often struggled to achieve an accuracy rate of over 75% on this dataset.
Some of the top non-LLM models that achieved high accuracies included:
Graphix-3B+PICARD — 77.6%
SHiP+PICARD — 76.6%
RASAT+PICARD — 75.5%
Most of these top-performing non-LLM models utilized the same Transformer architecture with some variations. These models differed from LLMs in the sense that they are not pre-trained but rather are trained based on the task at hand.
Post-LLM
After the introduction of LLMs in November 2022, the possibility of using them to solve the NLQ to SQL conundrum opened up. A multitude of new participants have entered this field, almost on a daily basis.
We explored this possibility as well where we began by conducting a thorough evaluation of multiple LLMs. We compared three variants from OpenAI (text-davinci, GPT3.5-turbo, and GPT4), Google Codey, and several other open-source alternatives.
After our assessment, we found that GPT4 had superior accuracy. However, due to its associated costs and rate-limiting constraints, it was not practical for our operational context. As a result, we opted for GPT3.5-turbo, which was the second-best performer.
We then evaluated our LLM-based solution using the Spider dataset, which yielded an impressive accuracy of 80%. This positioned us well beyond non-LLM approaches and close to the top-performing models on the leaderboard, some of which leverage GPT-4. This achievement is a clear testament to the capabilities and more importantly the possibilities that LLMs have opened up.
While definitely impressive, we also analyzed where the LLMs were dropping the ball (the missing 20%). Several consistent patterns became apparent:
At times, LLMs fail to comprehend the underlying logic of NLQs, leading to erroneous outputs.
LLMs have a tendency to hallucinate, occasionally producing column names that deviate from the context and introduce inconsistencies.
There are instances where the models introduce INNER JOIN operations between tables inappropriately.
LLMs occasionally perform JOIN operations on incorrect columns, skewing the intended outcome.
The models tend to yield results that include columns not explicitly requested.
These and some other errors appeared consistently across all LLMs examined, albeit with variations in performance among different models.
Our approach to address these issues
We used some of the techniques mentioned below to address these challenges:
Fine-Tuning Models: We attempted to fine-tune LLMs for enhanced performance. While it showcased increased accuracy in certain cases, they were very fragile for inputs outside of the training data.
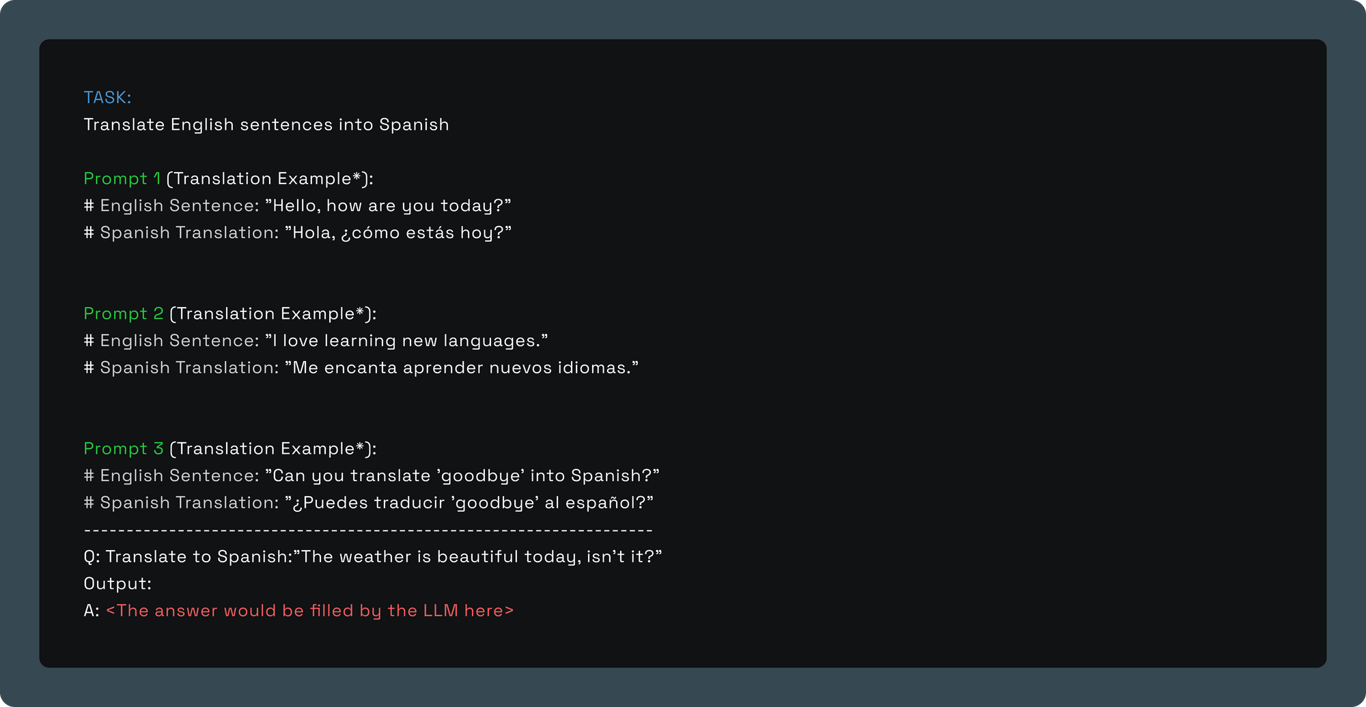
One-Shot/Few-Shot Examples in Prompts: We also integrated one or few-shot examples within prompts (example below) to enable in-context learning and steer the model to better performance on specific tasks or challenges.
However, it sometimes introduced bias and made errors in specific contexts.
Zero-Shot Approach: Another approach we used was the zero-shot method. This method relies solely on the task description in the prompt and the model’s pre-trained knowledge. The prompts are formulated to be clear and concise, containing essential contextual cues that guide the model to generate relevant and accurate responses, even for tasks it hasn’t been explicitly trained on.
Here are few basic examples of zero-shot prompting:
Breaking down the NLQ-to-SQL process: We also tried to divide the NLQ-to-SQL conversion into multiple stages: finding relevant tables and columns, categorizing query complexity, converting to SQL, and validating the SQL. However, this approach risked multiplicative errors at each stage.
Among these strategies, the zero-shot approach proved most successful for us, elevating performance to an impressive 80% on the Spider dataset.
A taste of the real world, beyond the Spider dataset
Transitioning from the controlled environment of the Spider dataset to real-world scenarios brings forth a host of additional challenges that make the NLQ-to-SQL task more complex. Here are some of these challenges:
Real-world data warehouses often have inconsistencies in table and column naming. This can lead to confusion and mistakes when selecting columns.
People tend to use abbreviations and business-specific jargon in NLQs, which LLMs may miss, affecting accuracy. Even when these terms are passed in the prompt, they are sometimes not picked up properly by the LLMs.
Real world business questions are far more complex than the academic queries of Spider dataset, challenging LLMs to grasp and translate multifaceted logic accurately.
NLQs often include terms that can be interpreted as either column headings or column values. Resolving this ambiguity correctly presents a significant challenge for LLMs.
Consider the NLQ, “Find the total number of priority customers.” To interpret this query correctly, an LLM must recognize that “priority” in this context is a specific value within the “customer segment” column, rather than a column heading. The desired outcome is to calculate the total number of customers falling under this specific “priority” category.
Providing additional contextual information is crucial for helping LLMs make this distinction accurately. However, the inclusion of extra data also increases the size and complexity of the prompt.
Business users are often shielded from certain conditions applied by analysts in queries. For instance, in order to obtain actual product sales, SQL might need to exclude test orders, a detail known only to the analysts. This can result in incorrect data being presented to business users.
At times, even when the correct database dialect is specified in prompts, LLMs may produce SQL that utilizes functions incompatible with the intended target database.
These are just a few of the complexities we encountered, and we acknowledge that they represent merely the tip of the iceberg. We have listed them here to underscore the intricate nature of NLQ-to-SQL translation in practical settings.
However, to be fair, it’s essential to acknowledge that LLMs have not been without their successes. In situations lacking ambiguity, LLMs have accurately generated 100+ lines of SQL code!
Our perspective on using LLMs for NLQ-to-SQL
The NLQ-to-SQL capabilities of LLMs are far superior to any other solution that existed prior to them. However, they are not 100% accurate.
This leads us to a crucial question: Does the current level of accuracy meet the requirements for practical business applications? In our view, it falls short. Allow us to elaborate.
A 20% error rate proves inadequate for businesses seeking dependable and consistent outcomes. Furthermore, when integrating this NLQ-to-SQL module into workflows that demand multiple layers of outputs, the overall accuracy of the entire process can significantly diminish. In a 3-step process, the accuracy would plummet to 51%.
That said, we firmly believe that LLMs will continue to advance in terms of accuracy. However, in their current state, LLMs may not seamlessly serve as plug-and-play solutions for business use-cases.
Therefore, the more relevant question for us is how we can leverage LLMs in their current state to address business challenges. To answer this question, we took a deeper look into the Jobs to be Done from a business perspective.
SQL is just a means to solve business problems
When it comes to day to day problem solving, businesses have to answer multiple questions before they can get to the root-causes they can act upon. (We have talked about this here.)
Our experience indicates that many of these questions can be organized into frameworks. This implies that dedicating valuable analyst resources to repeatedly troubleshoot the “Whys” is not the most efficient allocation of resources.
In our perspective, there is value in productizing these problem-solving frameworks along with the SQL queries previously created by company analysts to resolve these issues.
The next time the business needs to tackle a problem, they can simply ask questions in plain English. LLMs provide the capability to comprehend the context and parameters of the question, recognize the applicable framework for the given context, and swiftly conduct the analysis to provide the root causes.
It’s like having an AI companion that does the heavy lifting for them.
The result? Business can get to actionable insights instantly, without getting lost in the details of “Why.”
If you’re interested in exploring these possibilities, please reach out. We’d be happy to chat!